I recently brought a new laptop bag for day to day use. I had previously switched to a slimline messenger bag as I have been trying to carry less. My commute has extended by 40 minutes over the last year on days I go to the office. I have found that I actually need to carry slightly more to keep me amused and to see me through one or two days. For these reasons and the fact Sam, our cat, decided to pee on my previous bag it was time for a new one.
For a long time, I have been looking at Timbuk2 bags. Started in 1989, Timbuk2 initially started by selling quality messenger bags for cycle couriers. These days they have widened their range. I have heard many people that I know (and some I don’t) recommend these bags. They have a reputation of lasting and being hard wearing while retaining a unique look. They also have a reputation for lots of pockets.
To be honest I missed a good backpack after a year with a slim messenger. After a little browsing, I opted to order a Command Backpack in Jet Black.
I have now been using the bag for a little over 2 months and it’s fair to say it’s worth every penny. The bag states it can hold up to 30 litres but I have yet to fill it to capacity. There is a main compartment which I use for packing a hoodie, 2-litre bottle of water, project books, reading books and protein bottles. There is still a lot of room left. There is a second main compartment with several organiser pockets and pen and cable organisers. On the front, there is a small easy access pouch and a Tricot lined glasses compartment.
The main laptop compartment is placed on the back of the bag and unzips on three sides. It is Tricot lined and will hold up to a 15” laptop. I suspect this really means a 15” Mac but my current daily driver which is a 15.6” PC Specialist laptop does just fit. It was tight though. When you unzip the compartment there is also a small section for a tablet or a small notebook. To be honest this is where one of the negative aspects of the bag is to be found. I get that the design is TSA compliant but that is little comfort when trying to get your laptop out in a crowded train. Due to the three-sided zip and the weight of the main bag, it can be awkward to get the compartment shut. This is especially true when you have only one hand or if you have a travel mug or bottle in the side pouch. I have learned to master it but it took time.
The other negative point is the compression straps on the bottom of the bag. They are there to “pull in” the bag if you are not using all the available space. Unfortunately, this means that there is no bottom for the bag to stand on. Not a big issue but it took a little getting used to and a few bag tips.
This Command is comfortable. The shoulder straps are wide and so should fit most body shapes. Even fully loaded I don’t feel the bag is heavy. I really like this bag. It has more than enough space while being practical and it comes with a lifetime warranty. Barring the need to get used to the different positioning and zip system of the laptop compartment I would recommend this bag.
Have you got a recommendation for laptop bag brands or questions about the Command Backpack? If so then please contact me via twitter or email.
C# has switch statements much like many other programming languages. While they can be a useful solution in some situations they can also be a code smell.
When should you use a switch statement? When it makes the code’s intention clear or the code easier to read. For example:
if(myEnumeration.Value==1){// execute code for value 1
}elseif(myEnumeration.Value==2||myEnumeration.Value==3){// execute code for values 2 or 3
}elseif(myEnumeration.Value==4){// execute code for value 4
}elseif(myEnumeration.Value==5){// execute code for value 5
}elseif(myEnumeration.Value==6){// execute code for value 6
}else{// execute code for all other values
}
vs
switch(myEnumeration.Value){case1:// execute code for value 1
case2:case3:// execute code for values 2 or 3
case4:// execute code for value 4
case5:// execute code for value 5
case6:// execute code for value 6
default:// execute code for all other values
}
As you can see the switch syntax is cleaner as it removes the need for so many brackets. It also supports “fall through” functionality which makes it easier to see mixed clauses (such as values 2 and 3). I personally like the default label which makes it clear what will be done if no values are matched. Switch statements are ideally suited to enumerations and numeric conditional tests. They are also ideally suited to instances where there is a single execution task based on a successful match.
When should you not use a switch statement? When you are working with non-numeric values. When you have multiple lines to execute on a successful match and when you can see (or smell) an Open Closed Principle violation such as the following code:
As you can see this method is applying sorting to an enumerable SubscriptionsModel. Each case line is determining if it should order in ascending or descending order and the field to sort on. The way it is currently written means that if we add a new field into the SubscriptionModel class we would need to update the switch statement. This is far from ideal. An extra point I will make is that there is no case independent comparison here either. This is a reason I tend to not us switch statements with Strings. You have to sanitise the input as we know users can surprise use with unpredictable input.
Code like this is very common. However, C# offers a nice solution to the endless case branches, reflection. Using reflection will allow the above code to become:
This code uses a PropertyInfo instance which can be used to pass into the OrderBy and OrderByDescending methods. This allows dynamic rather than hard-coded parameters to be used removing the need to change the method when a new field is added. Mixing this into another C# favourite of mine, extensions, you might want to create a generic method such as
This is a basic implementation. I have shared this with a mid-level developer recently as a starting point. The challenge was to write an implementation that contains no if statement for the sort direction.
This post has shown that you should think about the way in which switch statements are used. While useful, they need to be used in a way that doesn’t violate the SOLID principles. If you have any feedback or comments around this post then please contact me via twitter or email.
This past week we pushed out a new site at Open Energy Market. Built using Hugo and deployed on Netlify it is the start of an expandable and agile site which we have big plans for.
Normally when I deploy sites on Netlify I migrate the domain nameservers over to Netlify as well. On this occasion, due to our subdomains and internal security, this was not an option. Instead, I had to set up the DNS for Netlify manually. While not hard, it was more buried in their documentation than it could be. I thought I would cover it here as a point of reference.
The first step is to associate your domain with your Netlify site. You do this by going to the Domains section of your site’s configuration. Here you will add your custom domain, www.myfabnewsite.com for example. When you save this then Netlify will also add a record for your naked domain. This is your domain without any subdomains such as www, myfabnewsite.com for example. This is to allow their automatic domain redirects to work.
To get your domain working you need to update both your naked domain and your www subdomains as follows:
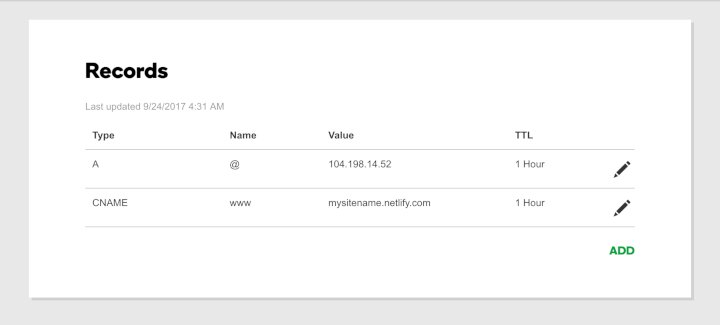
Update your DNS A record’s Value to 104.198.14.52 which is the Netlify load balancer’s IP address. Your A record will have a @ in the Name field.
Update your www CName record to point to the name of your Netlify site. A CName record is used to define subdomains such as www. The record to update will have CNAME in the Type field and www in the Name field. In the shots below (which are obviously not our real details for obvious reasons) you would take the openenergymarket-com-orig name from the Netlify site and add it to the CName record which is showing mysitename.Netlify.com below.
I would suggest that you reduce your TTL value on these records to the minimum value supported. This will reduce the amount of time it takes to test your changes. You can always change them later should you need to when you know it is working.
The final issue we faced once our DNS was set up was that Netlify had only issued a www.domain.com SSL Certificate. Netlify uses the Lets Encrypt authority to provide SSL certificates. It is all done automatically from a button click or when you add your Custom Domain. In this case, it had not created a certificate for the naked domain. It appears that you need to allow the DNS to correctly propagate. Once it has done so you can click Renew Certificate in the SSL section of your site. It then generates a wild card certificate for your domain which covers all variants of it. Naked and subdomains are all secured. It was just slightly frustrating that you have no control over this and the UI feedback was limited.
Now you should have your site running with your domain all secured. If you have any feedback around this post or have trouble with any of the steps then please contact me via twitter or email.
This post is circling back around on a topic I have covered before, The Open Closed Principle. The Open Closed Principle is part of the Solid design principles. The principle states
“Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification. That is, such an entity can allow its behaviour to be extended without modifying its source code.”
I came across the code I present below this week in a pull request and thought I would cover my suggested change of approach here. The post is also about recognising code smells around the Open Closed Principle and one potential way to fix them.
First, what is a code smell? For first time readers here, Wikipedia states:
“In computer programming, a code smell is any characteristic in the source code of a program that possibly indicates a deeper problem. Determining what is and is not a code smell is subjective, and varies by language, developer, and development methodology.”
So really when people are talking about code smells they are referring to a range of deeper problems. In the case of the code below this was displayed as repeated methods call of identical structure.
privatestaticvoidRunExpiryReminderService(){try{varnotificationsSent=_expiryReminderService.sendNotifications();if(notificationsSent!=0){successfulNotifications.Add("MOP/DC Expiry Reminder Service",notificationsSent);}_consoleWriter.WriteLineWithNewLine("Expiry Reminder Service run succesfully");}catch(Exceptionex){failedNotifications.Add("MOP/DC Expiry Reminder Service",ex.Message);_consoleWriter.WriteLineWithNewLine("Expiry Reminder Service run with errors");}}privatestaticvoidRunNotificationsForMetersWithNo_MOP_DC_Data(){try{varnotificationsSent=_customerEngagementService.sendNotificationsForMetersWithNo_MOP_DC_Data();if(notificationsSent!=0){successfulNotifications.Add("Notifications For Meters With No MOP/DC Data",notificationsSent);}_consoleWriter.WriteLineWithNewLine("Notifications For Meters With No MOP/DC Data run succesfully");}catch(Exceptionex){failedNotifications.Add("Notifications For Meters With No MOP/DC Data",ex.Message);_consoleWriter.WriteLineWithNewLine("Notifications For Meters With No MOP/DC Data run with errors");}}
As you read through these methods it is really clear that each is completing the same task. They run a service method which is a wrapper to execute a query and send the results via email. They add the name of the service method executed if successful to a tracking list. They then write a log entry to the console. If they fail for any reason then they add the name of the service method to a tracking list of failures. They then write a log entry to the console. All very simple and each of the five methods does the same thing (I showed two above). The only difference is the service method call.
A few things instantly stood out:
The shape of the methods was identical. This is a similar phenomenon as code smells. If you can spot that two methods are the same shape then it is highly likely that they are doing almost the same thing.
The service methods are all parameterless methods that return an integer. This represents the number of records sent in the notification.
To extend the application logic for another internal notification new code would be needed. A new service method would be needed and executed in the new management method.
The code was in no way open to extension and did, in fact, require modification for each subsequent change. Given the unique signatures of the service methods, I felt using a Func<int> was an obvious solution.
For the uninitiated C# provides two mechanisms to implement type-safe delegate function pointers. The Func and Action mechanisms can be used to reference and invoke a delegate method. The main difference is that Actions can execute methods that do not return a value. Func delegates are expected to return a value.
Back to the code. Let’s look at one of the methods and break it down.
privatestaticvoidRunExpiryReminderService(){try{varnotificationsSent=_expiryReminderService.sendNotifications();if(notificationsSent!=0){successfulNotifications.Add("MOP/DC Expiry Reminder Service",notificationsSent);}_consoleWriter.WriteLineWithNewLine("Expiry Reminder Service run succesfully");}catch(Exceptionex){failedNotifications.Add("MOP/DC Expiry Reminder Service",ex.Message);_consoleWriter.WriteLineWithNewLine("Expiry Reminder Service run with errors");}}
The first thing each of the repeated execution methods does is to execute the service method. If the service method returns a value then a service method name is added to the successfulNotifications list. If it fails then the service method name is added to the failedNotifications list. Lastly, each method is logging a success or failure message. From this, we can identify the common fields of data required by each repeating method. So to group those fields together we can define a POCO class. So let’s do that
This POCO just defines properties to store the items identified above. It also has an additional property, ExecutionDays, which I will come to later. Now let’s see how these methods were called.
RunExpiryReminderService();//Services which run weekly
if(DateTime.Today.DayOfWeek==DayOfWeek.Monday){RunNotificationsForMetersWithNo_MOP_DC_Data();RunLoaExpirationNotifications();RunNotificationsForMetersWithContractDueToExpiry();RunNotificationsForCompaniesWithAllUsersInactivated();}
So it would seem that some of them should only be executed on a Monday. (For context this code is executed daily). Hence why when defining the POCO above I included the ExecutionDays property. This allows the configuration to outline which days the service methods are run. I cleaned up this logic and added a method to return a list of InternalNotification objects. The method does nothing more than define the InternalNotification objects.
varinternalNotifications=newList<InternalNotification>(){newInternalNotification{ServiceMethod=_customerEngagementService.sendNotificationsForMetersWithNo_MOP_DC_Data,Name="MOP/DC Expiry Reminder Service",SuccessMessage="Expiry Reminder Service run successfully",FailureMessage="Expiry Reminder Service run with errors",ExecutionDays=newList<DayOfWeek>(){DayOfWeek.Monday,DayOfWeek.Wednesday}}};
The next thing was to take one of the executing methods and modify it to work with the InternalNotification objects. I also wrapped the code with a foreach loop to execute over a list of InternalNotification objects. This list is generated by filtering the full list of InternalNotification objects by the current day. This means we know we are only executing the notifications for today.
The last step was to remove the old, repeated methods. With that the implementation was complete and we would be able to extend the new code by simply adding the configuration for a new service method to be executed. The processing code would no longer need to be modified to support new notifications.
With the idea scoped out I updated the PR with full details and an explanation of how this approach reduces duplicated methods and addresses the violation. I also extended my comments to recommend that to fully meet the Open Closed Principle the developer should use reflection to load Notification configuration objects based on an abstract interface to define the InternalNotifications. This would allow them to remove the utility method that defines the configuration and the list of notifications.
If you have any thoughts about this post then please contact me via twitter or email.
In this post, I want to highlight a couple of observations about the use of conditional if statements. All languages have a variety of the humble if statement. Programs would not be able to function without them and the logic they provide. Some might say they are the basis of very early AI but I digress.
The basic outline of an if statement is as follows:
if("a specific condition equates to true"){DoSomething();}else{DoSomethingElse();}
This say’s that if the tested condition is true then execute the DoSomething() method. If not execute the DoSomethingElse() method. All pretty straightforward.
But, there are some obvious issues that we should look out for. We do not want to make our code unreadable or hard to understand.
The first observation relates to when many conditions are tested in one go which makes reading the if line a little harder. If reading the conditional test logic is hard then reversing it to understand how you get to the else is even harder.
if((person.Age>18&&person.Age<25)&&group.Name=="Test Group 1"||group.Name=="Test Group 5"){DoSomething()}else{DoSomethingElse();}
Vs
varisPersonInTargetAgeRange=person.Age>18&&person.Age<25;varisATargetGroup="Test Group 1"||group.Name=="Test Group 5";if(isPersonInTargetAgeRange&&isATargetGroup){DoSomething()}else{DoSomethingElse();}
Creating well-named variables and using them in the test condition makes it much easier to read. It is also easier to understand the reverse logic when determining how the else block is reached.
The next problem is the use of deep nested if statements. I have seen a lot of examples of this lately. Code such as:
The more conditions that are added add a further level of nesting. Code usually ends up like this due to extending requirements. Deep nesting makes it hard to understand the logic that leads to the actual execution of a piece of code. It becomes a lot harder when you have else clauses at multiple levels as well.
The final issue I want to cover is the use of an if statement to wrap the body of a method. This is another approach which I have seen a lot lately. Something like:
Why? Why would you write this? You should look to exit your functions and methods at the earliest opportunity. This is why approaches such as parameter checking are available in most languages. There are patterns that mean you can check and exit out if you get a null or unexpected value. Wrapping your method body like either of these examples is a clear signal you need to refactor your code.
if statements are a core part of most programming languages but you need to ensure their use does not result hard to understand code. If you find yourself nesting if statements or if you find that your test conditions span multiple lines then you almost certainly need to refactor your code.
If you have any thoughts about this post then please contact me via twitter or email.
 Welcome to my site and blog. You can find out about me and read my thoughts on code and technology, start-ups and building things.
Welcome to my site and blog. You can find out about me and read my thoughts on code and technology, start-ups and building things.