2020 has been not the year anyone has expected. I am sure I am not alone in finding it hard to process everything that has been going on. From the COVID 19 pandemic and its impact on life through to the sheer horror that is the non-complete, Brexit deal through to the US elections next month. By the time I got to May, the changes caused by the lockdown, the amount of work I had on and the need to carve out some headspace meant something had to give. Unfortunately, it was my blog.
The impact of the lockdown for everyone is significant. I have so many thoughts about this, it could be a post in its own right. I feel that the initial UK lockdown in April was backed 100% by everyone as it was a concrete effort to get on top of the virus. My fear as we start October is that the various plans for Tier systems and the lack of clear and consistent approaches throughout the UK will result in people losing faith in the science. I hope I am wrong.
I have spent the last six months working on some interesting projects. This has lead to working with some new tech stacks and frameworks. I have a lot of ideas for posts going forward to share some of what I have learnt. I also have plans to try some new hobbies as the dark evenings draw in and am looking for extra inspiration. All suggestions welcome
So onward …
As always, if you’d like to contact me then reach out via twitter or email.
Sitting all day is the new smoking according to certain research over the last few years. In fact, the idea that sitting all day while completing your office work was flagged bad for you as early as 1961. Yet we all do it. Like smoking though, habits can change and over the last 15 years or so standing desks have become commonplace in a lot of offices.
I used to work standing up when a significant part of my role was coding. I had a stand that elevated my laptop so my arms were in the right position. Buying the stand was meant to be a small experiment but I ended up working like that for a few years unless I was on the road. What I didn’t realise was that because the screen was not elevated I was looking down in a position that was not ideal. In fact, it basically mimicked the position you are in when using a laptop directly on the desk. As my role evolved and required more calls and meetings, for some reason I went back to sitting.
Over the last six months, I have found that I been sitting for longer than normal and my lower back had developed a bad ache. I started to look at standing desks again and actually purchased one. Like before, I was unsure how I would get on and set a budget which if the experiment failed I wouldn’t be too upset about. My new set up is now:
(Actually, that is how it looked when I set it up. I have now tidied up the cables and power supplies so they are out of view.)
I am really pleased with how I am getting on with the setup. Moving to 3 screens from only a laptop for the last couple of years has massively helped my development workflow. How have I found standing? The first couple of weeks I built it up by 30-minute increments each day. Now I am standing pretty much all day unless I am talking to clients. I tend to sit for those calls so I am looking square at the webcam in the laptop. The desk has a manual hydraulic mechanism so positioning the desk is painless.
How is the back pain? A lot better, in fact I have not felt it in over a month. In saying that I am mindful of the potential side effects from standing. Research shows that it is not a magic bullet. The effect on the number of calories you burn during the day is negligible. The benefit on the heart is not massive either. Research shows that if these are your key drivers for trying a standing desk you should look at treadmill desks instead. Standing for prolonged periods can cause leg and back pain (irony?) It is important that if you choose to stand you pick a good anti-fatigue matt to reduce the risks.
Since we’re almost all working from home at the moment, people have the time to experiment with how they work. I recommend trying a standing desk and seeing how you feel against sitting in a chair all day. I find that I walk more by working standing up as when I have a problem I walk around the house to think about it instead of slumping in my chair. On calls, I pace around the garden more than I did when I chair bound. You don’t have to pay a lot for a desk to start with either. A pile of books or two can create the perfect solution. Give it a try and see if you come away feeling more energised and less tight after a day at work.
If you have any questions or recommendations for standing desk’s or additional tips then let me know via twitter or email.
This week I experienced my first fatal failure under Linux for a very long time. I was restoring a project to work on and updating the Jekyll framework which was refusing to play nicely. I applied a recommended fix from the Manjaro repo’s and my laptop froze. Upon rebooting it just panicked and refused to boot.
This wasn’t a huge problem I thought, I will just reinstall and apply my dotfiles and be up and running. Only, what the experience taught me is that it is never that simple. Since switching to my latest work laptop I had not bothered setting up local backups. Why? Well, all my vital data now lives in one of two clouds and although I have local copies recovering that is easy. What you forget are all the small settings, fixes and changes you make bit by bit, day by day as you go about your work.
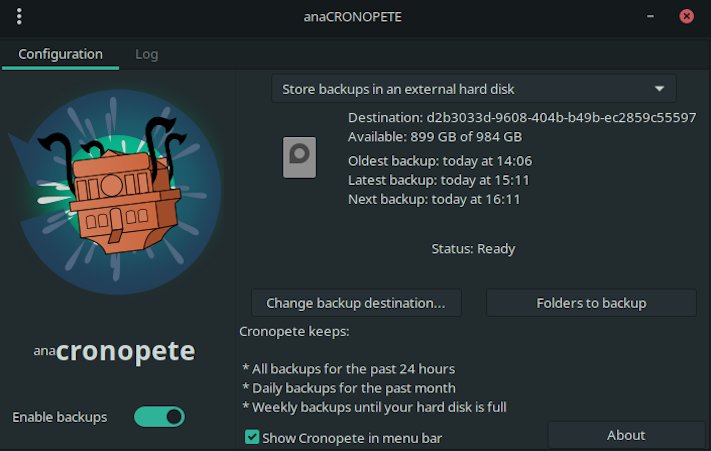
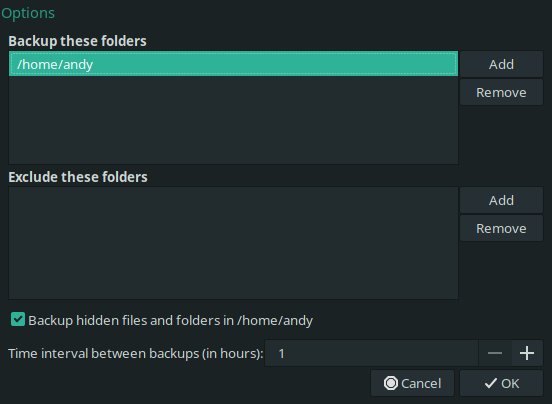
Getting the OS installed took 15 minutes and the first thing I wanted to set up was local backups. I read up on the latest state of Linux backup solutions and opted for Cronopete. The application is a clone of Apples Time Machine and it is simple to set up and running. Once installed, open the application and select a backup location. I chose an external hard drive and opted to back up all files in my home directory (including hidden files). I set the option to back up to an hour and set it off on it’s first back up.
To be honest I thought it would have taken quite a while on the first back up but it had my drive replicated in less than 15 minutes. Cronopete keeps files on the following basis:
One copy per hour is kept for the last 24 hours.
One daily copy for the last 15 days.
One weekly copy for the rest.
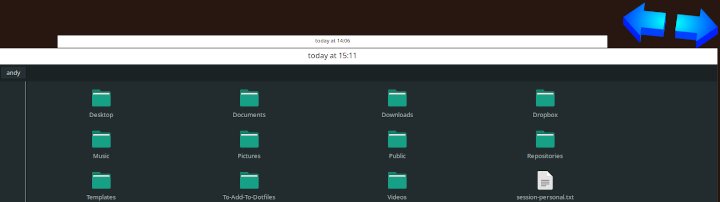
If you need to recover the files you can select the “Restore Files” option from the applications system tray menu. This brings up what is a functional UI (not the best) which allows you to choose the date at which to restore your files.
If you have any questions about the configuration or restoration of files from Cronopete let me know via twitter or email.
Facebook divides opinion. It defined an entire technology genre and has since gone on to become one of the leading online marketing and advertising platforms. This is something that a large percentage of their users do not realise. People are sharing their entire lives and personalities on the platform while sacrificing this data to be able to keep in touch with friends and family. They then seem surprised when an advert appears that relates to them.
In January Facebook finally released the Offline Activity tool. This allows you to see which companies share data with Facebook about you and your browsing habits away from Facebook. This data sharing has been enabled as part of the Facebook Business Tools for some time. This meant that when I go clothes shopping, for example, a site will share what I have browsed for and what I finally purchased. This explains why the adverts you see are so targeted. Of course, to increase the chance of you clicking an advert much higher, Facebook wants as much data about you as it can get. If they know you well enough, they can ensure the adverts you see are relevant and appealing. The downside to this is that any site can embed these tracking tools. This could include fake news sites or sites that have dubious intentions.
The good news is that you can disable who can share data with you. Like all Facebook Privacy controls it is well hidden and not promoted. To see what data they have on you:
Click the menu at the top right of Facebook and then select Settings & Privacy.
Click Settings.
Look in the left-hand column of the page and you should see a menu item called “Your Facebook Information” which you should click.
In the main page content, you will see Off-facebook Activity. Click this link.
Once you are are in the Off Facebook Activity page you can view who has been sharing your browsing habits with Facebook. You can also clear the history of this shared data and update your settings to prevent them from collecting this data.
From a data privacy point of view, the less Facebook knows about me the happier I am. While I do have an account it is only to stay connected to a very specific group of people. To do that should not mean I have to sacrifice my privacy.
If you have any thoughts about Facebook or the way they value revenue over privacy let me know via twitter or email.
I love static sites for many reasons and Jeyll is still a firm favourite when I need to throw together a simple site. One thing I hadn’t hit with Jekyll before was handling different environment settings and basic secrets. As with most things it was easy if not obvious at first how to handle it. There was also not much reference material other than the documentation. So here is a simple overview.
Setting Up & Configuring Your Configuration Files.
Jekyll gives you the ability to specify what configuration files are processed at build time via the -c command line switch. If you use this then you can pass an argument that is a comma separated list of configuration files. So to add one or more additional configuration files you:
Create your secret/environment file. This file should be stored in the root of your project (i.e. the same level as _config.yml). I called mine _environment.yml. This is a standard YAML file which you can add key value pairs such as:
The other command switches here provide hot reloading of changes (–livereload) which occurs when Jekyll rebuilds automatically on file changes (–watch). If you have dated content then the –future will allow you to see the content locally before the publish date.
So far all really easy. When you come to build your site for publication you can just update the build command to include the
$ jekyll build -c _config.yml,_environmet.yml
Using Your New Configuration Values.
Variables added to these configuration files can be accessed via the siteliquid variable. This means they can be added to pages very easily using the standard pattern.
If you need to use these variables in your JavaScript or CSS then don’t forget you can preprocess these files just by adding frontmatter markup to the top of your files such as:
---layout:null---
This means you can access the variables from these configuration files using the same markup as above.
 Welcome to my site and blog. You can find out about me and read my thoughts on code and technology, start-ups and building things.
Welcome to my site and blog. You can find out about me and read my thoughts on code and technology, start-ups and building things.